

Через несколько лет после внедрения автоматизированных систем организация может оказаться в ситуации, когда загрузка оборудования приблизилась к максимуму, производительность выполнения ежедневных штатных процедур упала, как следствие, встал вопрос о покупке более мощного железа. Можно ли максимально отсрочить этот момент? В большинстве случаев можно. О практике оптимизации производительности баз данных Oracle делится Александр Кондиайн, главный архитектор по хранилищам данных департамента аналитических систем.
Каждый ИТ-специалист, занимающийся поддержкой инфраструктуры, знает, что через несколько лет эксплуатации система, работающая на базе данных (например, на БД Oracle), теряет производительность. Например, запрос к серверу, который изначально выполнялся буквально одну секунду, стал отрабатывать за 15 или даже 20 секунд. При этом довольно часто отчет о производительности (AWR-отчет) может свидетельствовать о нормальном функционировании ПО. Что же делать? Конечно, выявлять такие запросы и оптимизировать их.
Как вы знаете, АБС и системы на основе хранилищ данных (то есть OLTP- и OLAP-системы) по-разному используют базы данных, поэтому и методики оптимизации у них разные. На примере простейших графиков мы расскажем, в чем их отличие, и, опираясь на собственный опыт, посоветуем, как с помощью инструментов Oracle Enterprise Manager и SQL Monitoring найти ошибки в проектировании и коде, а за счет параллельного выполнения, секционирования и других приемов «выжать» из оборудования максимум его возможностей. Следуя этим рекомендациям, вам удастся продлить срок его службы.
Загрузка сервера в системе координат
Для начала представим себе, что делает сервер БД, когда обрабатывает запрос. Для этого построим график, где по оси X — время, а по оси Y — мощность (или загрузка) сервера (рис. 1). В реальности загрузка состоит из нескольких компонентов, включая загрузку процессора, памяти и системы хранения данных, но для простоты в нашем случае будем ориентироваться на некоторую «общую» загрузку.
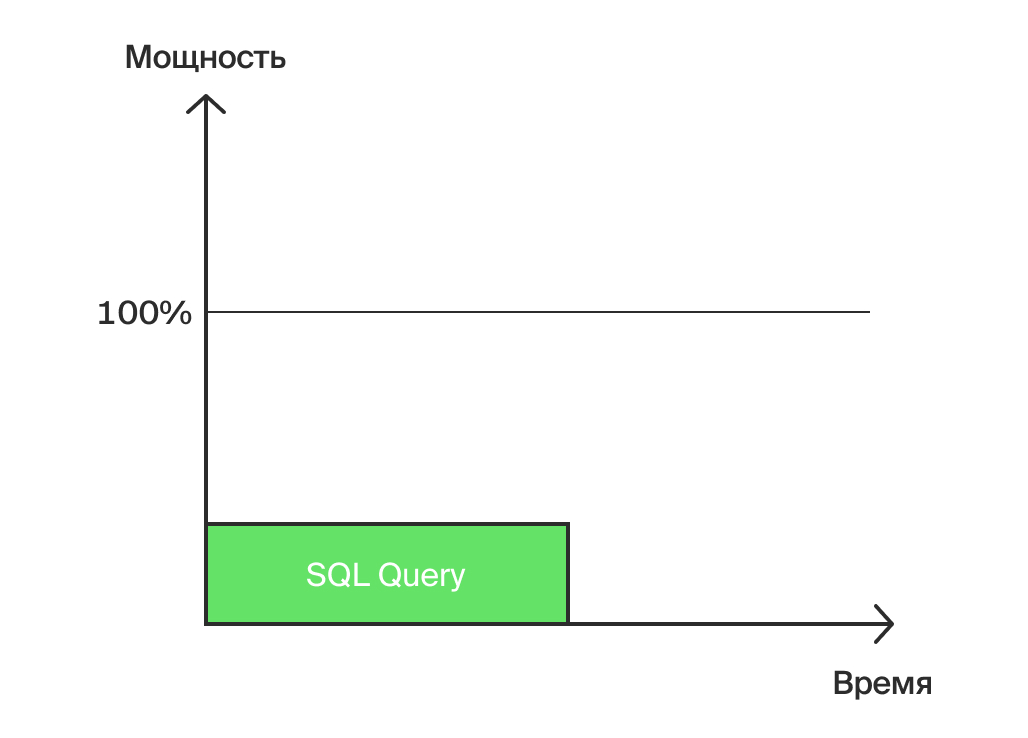
Одиночный запрос, выполненный на сервере (Рис.1)
На рисунке 1 показан одиночный запрос. Его выполнение затратило какое-то время и некоторую мощность сервера, поэтому физический смысл нашего запроса — работа. Объем этой работы можно измерить в абстрактных «условных единицах». Именно в этих единицах оптимизатор Oracle измеряет стоимость запроса. То, что мы видим в разделе Cost в плане запроса, является оценочной стоимостью работы сервера по выполнению этого запроса.
Оптимизация OLTP-системы
Нагрузка в OLTP-системах
Теперь посмотрим, как выглядит нагрузка в OLTP-системе (рис. 2). Представьте, что перед вами многопроцессорный сервер, способный решать несколько задач одновременно. Вся нагрузка на схеме отображается как набор «кирпичиков» — запросов, каждый из которых выполняется некоторое время и занимает, например, один процессор.
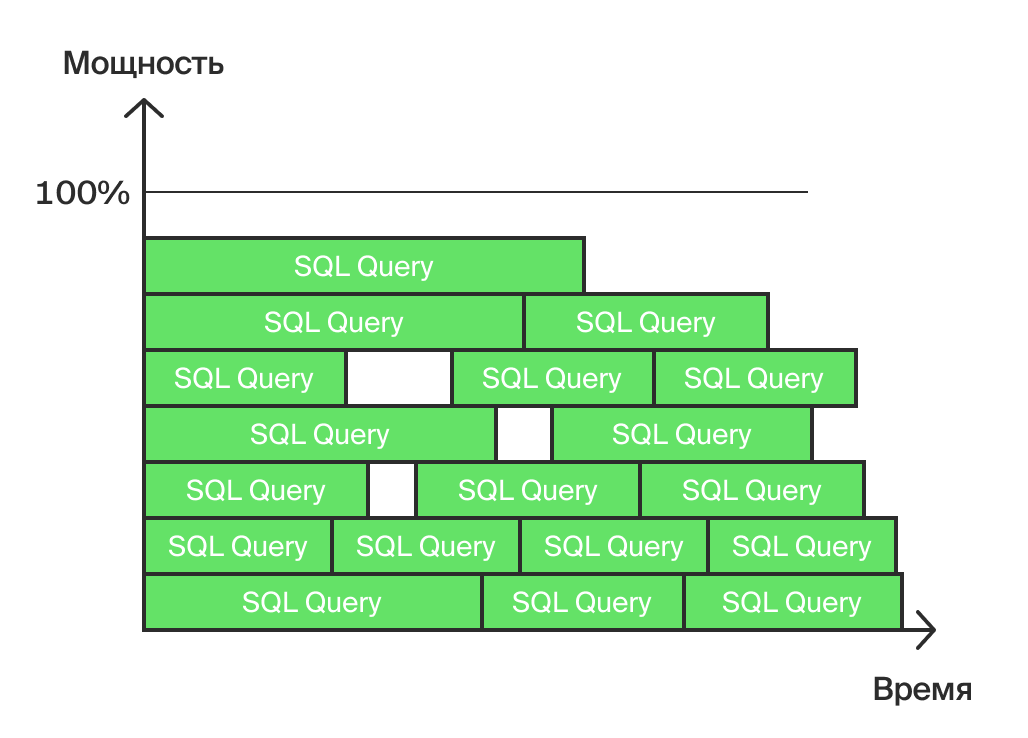
Нагрузка в OLTP-системе (Рис. 2)
По мере роста количества одновременно запущенных процессов каждый из них выполняется все медленнее. Причина в том, что сервер затрачивает дополнительные ресурсы на переключение между процессами, а кроме этого, обычно СХД является более «тонким» местом, чем процессоры. Если такая «кирпичная» стена достигнет в высоту 100%, то сервер «встанет» — новые процессы будут помещаться в очередь (если у системы предусмотрены ресурсы на это). Таким образом, глобальная задача оптимизации — как можно дальше отодвинуть момент полной загрузки сервера.
Для уменьшения нагрузки мы рекомендуем выбрать некоторое количество одинаковых процессов, которые можно оптимизировать. На нашем графике (рис. 3) они окрашены синим.
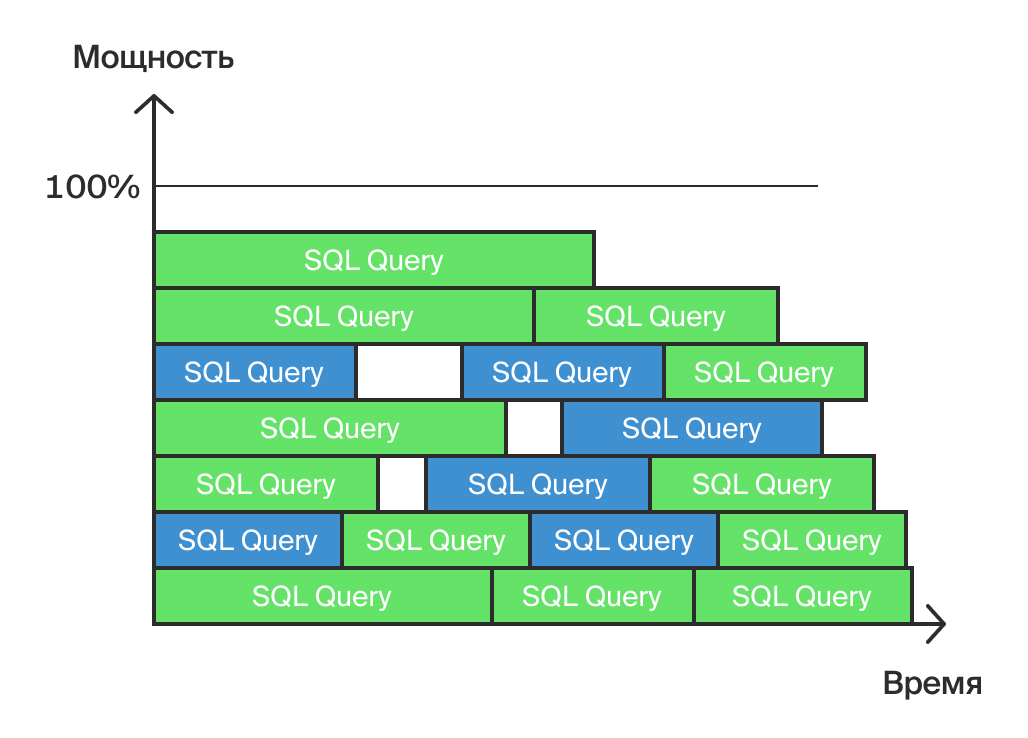
Выбор одинаковых процессов с целью оптимизации (Рис. 3)
Давайте сократим эти блоки в 2-3 раза и посмотрим, что получится (рис. 4).
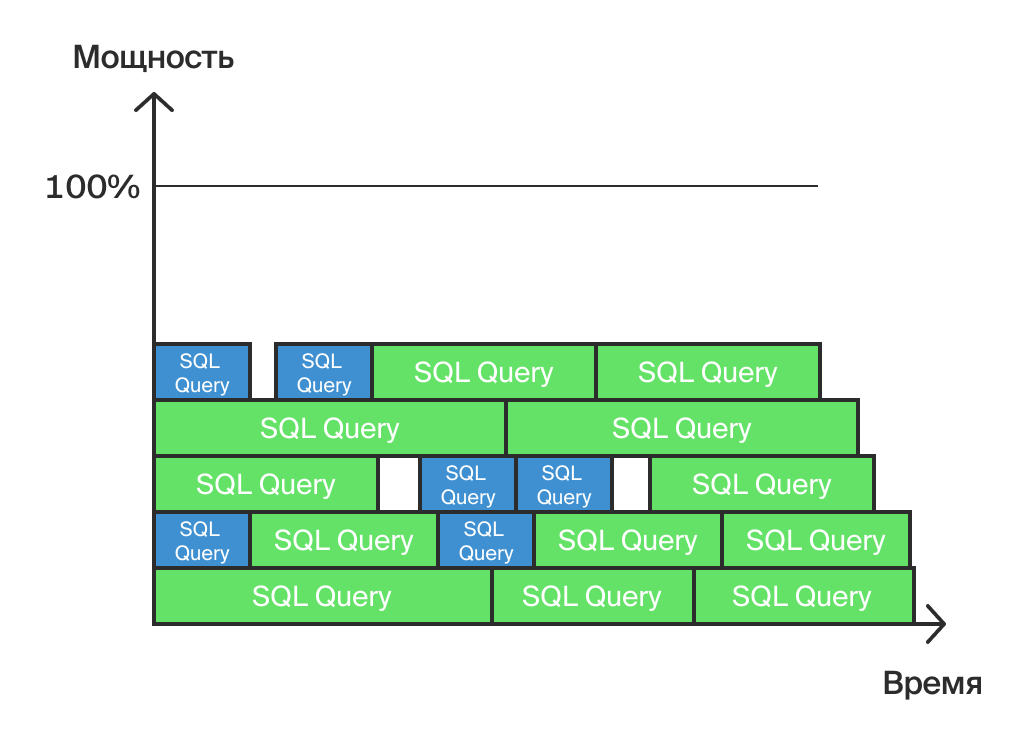
Рис. 4. Результат оптимизации
Как видите, сервер завершил их выполнение раньше, поэтому появилась возможность перераспределить процессы между процессорами. Таким образом, не только уменьшилась общая площадь фигуры (работа, произведенная сервером), но и максимальная загрузка снизилась на две условные линии, отодвинув, таким образом, критический момент полной загрузки сервера.
Упомянутая «общая площадь фигуры» примерно соответствует такому важному показателю AWR-отчета, как DB Time. По сути, это общее время работы сервера за период формирования AWR-отчета — The wall time, или Estimated. Например, если отчет выпускался за 1 час, количество процессоров в системе 16, а DB Time в отчете равен 8 часам, это означает, что средняя загрузка сервера составила 50%.
Показатель DB Time удобно использовать как меру произведенной оптимизации (конечно, с учетом отклонений нагрузки, потому что в промышленной среде редко бывают одинаковые по нагрузке дни). Но в целом, если сегодня это время в два раза меньше, чем вчера, день был примерно таким же, и перед снятием сегодняшнего отчета были установлены обновления по оптимизации, то можно предположить, что эти обновления сыграли свою роль.
Ищем «узкие» места
Другой метод — тестовые базы. На более слабом, чем промышленное, оборудовании «внезапно» начинают медленно работать отдельные рутинные операции. В промышленной среде они выполняются еще «терпимо», например 2 секунды, а на тестовой — 10, а то и 20 секунд, что уже становится заметным. И выясняется, что какая-то маленькая незаметная функция уже давно работает с плохим планом запроса.
Более инструментальный подход — AWR-отчет. В специальной секции он показывает top queries — какие из запросов заняли наибольшее DB Time, а также количество выполнений.
Могу привести еще более действенный метод — использование Oracle Enterprise Manager (EM).
Для работы со сколько-нибудь серьезными системами использование Enterprise Manager не только желательно, но и строго необходимо!
Решаем проблемы с производительностью
Исследование проблем с производительностью в Oracle без этого инструмента сродни изучению клеток без микроскопа. EM предоставляет возможность наблюдать нагрузку в реальном времени, в разрезе самых тяжелых запросов и пользовательских сессий. Кроме того, он умеет сам выделять top неоптимальных, по его мнению, запросов. Для них (а также для любых произвольных запросов по требованию) можно провести профилирование и получить советы по оптимизации — построить определенный индекс, изменить план запроса с возможностью его зафиксировать (baseline) и так далее.
Взглянем на одно из окон EM (рис. 5). Зеленая площадь — CPU, синяя — дисковый ввод-вывод. Хорошо, когда практически вся работа заключается в этих двух видах загрузки, как в нашем случае.
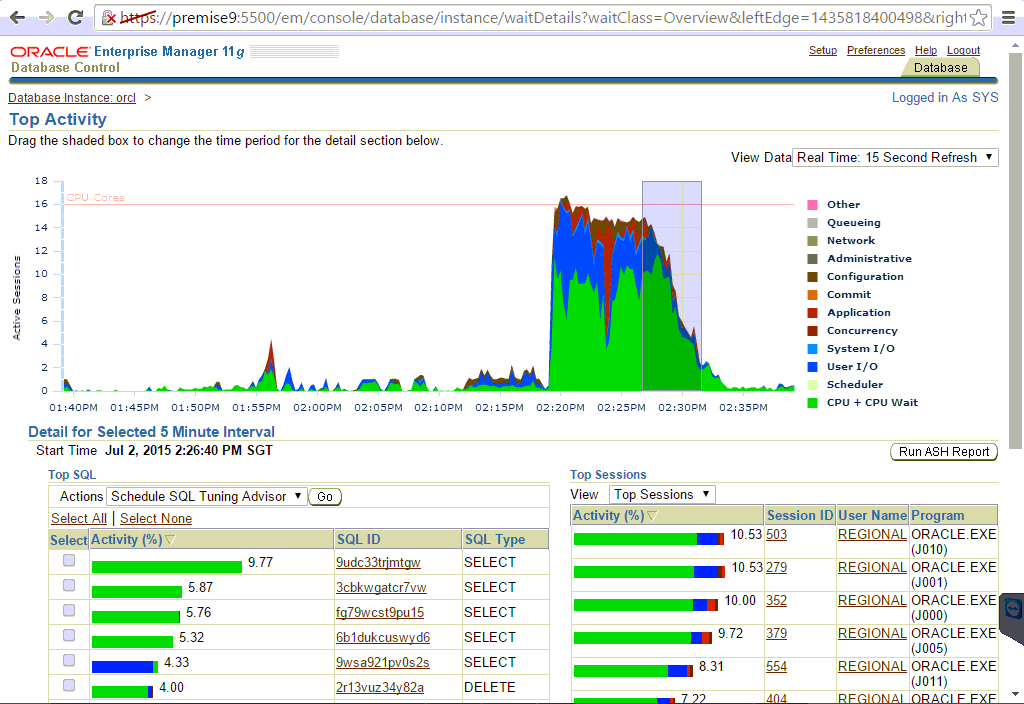
Отражение разных видов нагрузки в Oracle Enterprise Manager (Рис. 5)
Одна из самых мощных возможностей EM — SQL Monitoring (рис. 6). С его помощью мы можем в режиме онлайн отслеживать запросы, которые при настройках по умолчанию отвечают одному из двух критериев: либо длятся более 5 секунд, либо осуществляются в параллели. В окне мониторинга видно, на какой стадии выполнения находится запрос, таким образом, можно прогнозировать время его завершения. Окно является активным Flash Plugin и позволяет изучать практически все аспекты обработки запроса — от общего количества считанных/записанных байтов до тонкостей параллельного выполнения. При желании SQL Monitoring запроса можно сохранить в файл для последующего изучения.
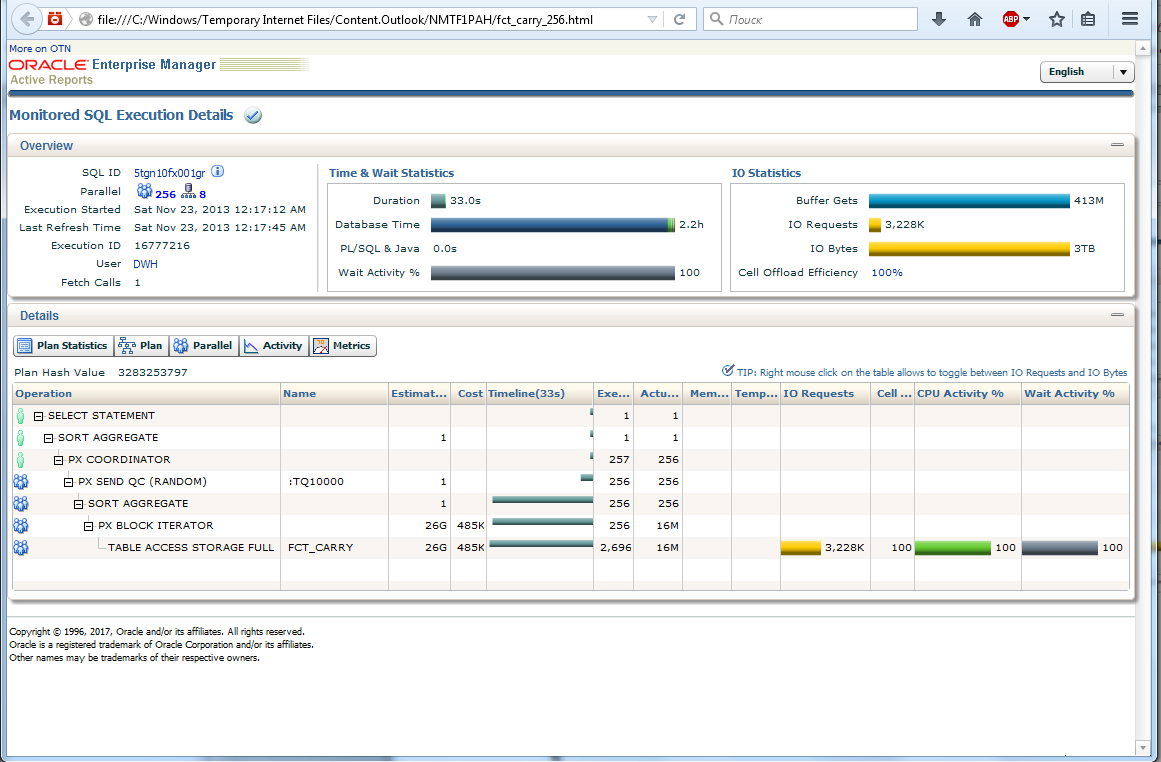
Пример окна SQL Monitoring (Рис. 6)
В соответствующих разделах панели SQL Monitoring отражаются диаграмма Ганта, количество операций ввода-вывода, потраченное время CPU и время ожидания. И эти параметры показаны для каждой операции из плана запроса. Проанализировав данную информацию, вы поймете, можно ли запрос оптимизировать и каким образом.
Вот как в SQL Monitoring выглядит пример «плохого» запроса (по отбору данных для работы в OLTP-системе), который постепенно стал работать более 20 секунд (рис. 7).
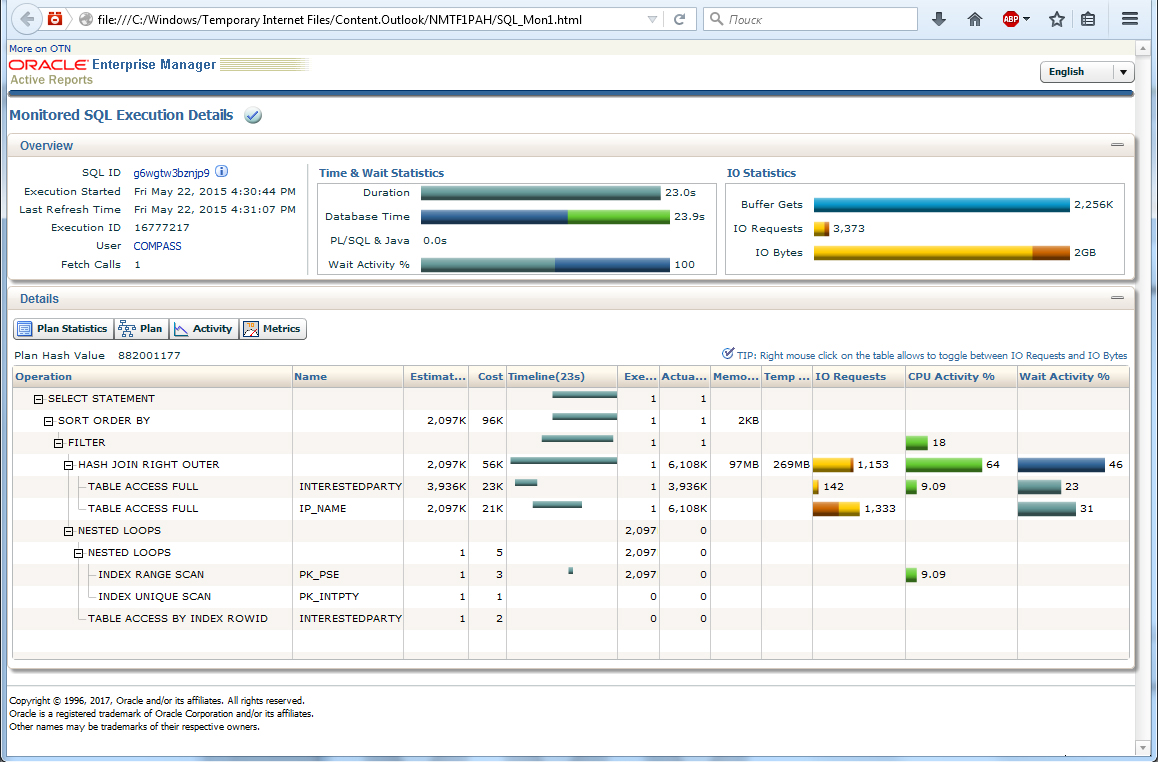
Пример «плохого» запроса (Рис. 7)
После изучения данный запрос путем несложного переписывания был оптимизирован и стал выполняться не более 1 секунды. Пользователи были счастливы!
Иногда бывают и совсем неожиданные результаты. Так, в одной большой промышленной среде замена в маленькой функции выражения «sUser:=user» на «select user into sUser from dual» дала снижение общей нагрузки на 10%. Правда, речь шла о 8 версии Oracle.
Оптимизация OLAP-системы
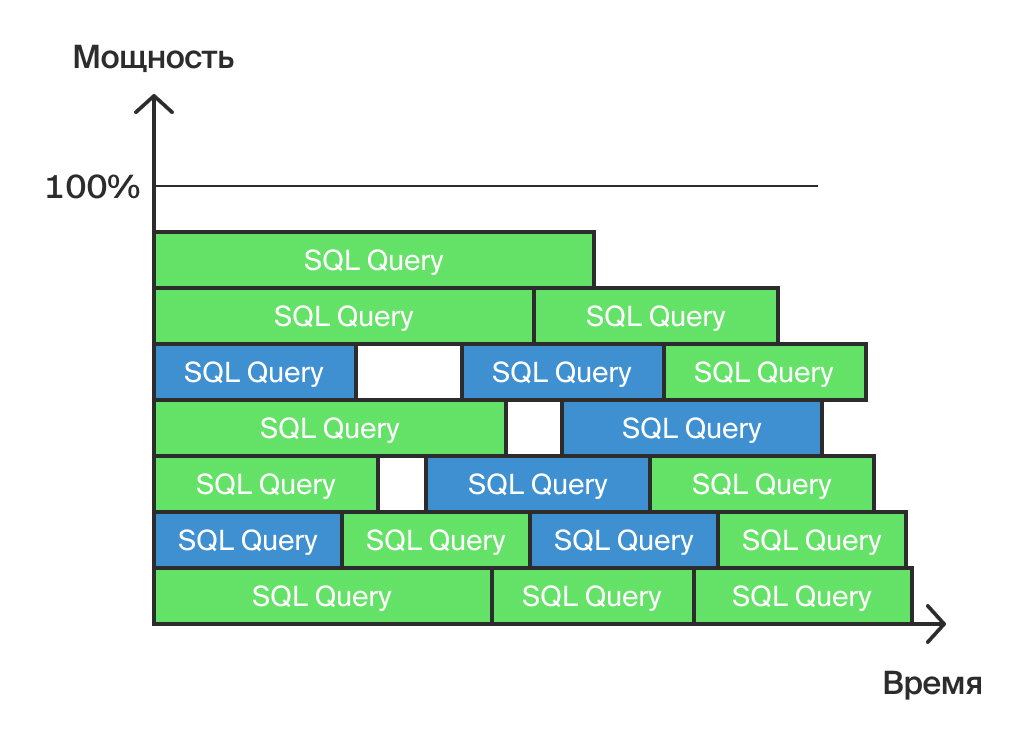
Рассмотрим типичный вид нагрузки на OLAP-систему (рис. 8).
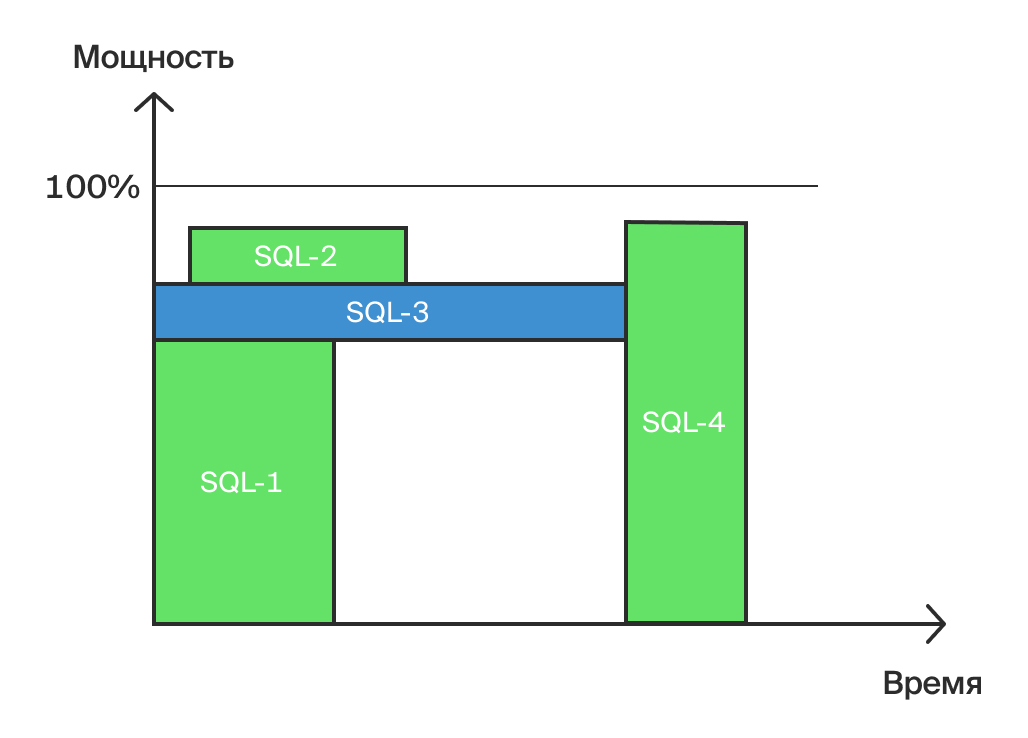
Нагрузка в OLAP-системе (Рис. 8)
Сразу замечу, что все сказанное выше про оптимизацию в OLTP сохраняет свою актуальность и для OLAP. Но есть и отличия: в OLAP меньше запросов, но они более сложные и требуют большего времени на выполнение. Кроме того, зачастую их обработка осуществляется в параллельном режиме.
Кстати, о времени ожидания: в OLAP может считаться нормальным запрос, который работает порядка часа, и пользователи готовы ждать его окончания. Процесс получения финальных данных обычно требует многочасовой работы сервера и включает этапы загрузки, перегрузки, валидации, расчета и т.д. Здесь ожидания те же — чем раньше получены данные, тем лучше, но оптимизации требует весь критический путь в целом. Проще говоря, пользователи будут счастливы, если ежедневно будут получать готовые данные не в 15:00, а, скажем, в 11:00, в идеале же — к моменту начала рабочего дня.
На нашем рисунке (см. рис. 8) выделен запрос SQL-3, который лежит на критическом пути и выполняется некоторое время. Преобразуем его из горизонтального «кирпичика» в вертикальный и получим совершенно другую картину (рис. 9).
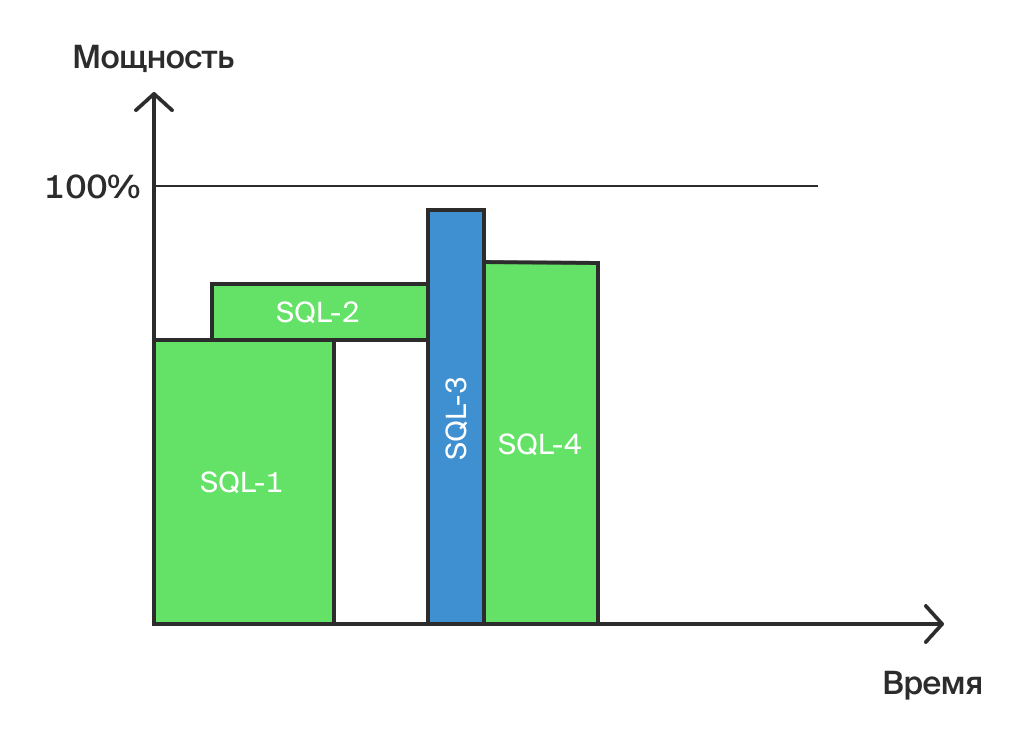
Результат оптимизации (Рис. 8)
Общее время выполнения всех четырех запросов значительно сократилось (сдвинулось влево). Это и есть главный результат оптимизации OLAP.
Интересно, что обычно после такого «переворачивания» общая площадь «кирпичиков» увеличивается, то есть сервер выполняет больше работы (накладные расходы на управление параллельными процессами). Но если ресурсы для такого запроса есть, и в это время нет нужды выполнять другой критически важный запрос, то объем работы не важен — важно меньшее время выполнения.
Конечно, действовать таким образом нужно обдуманно, учитывая наличие других возможных процессов в то же самое время: ввиду нехватки ресурсов они могут быть заблокированы.
Примеры модификаций
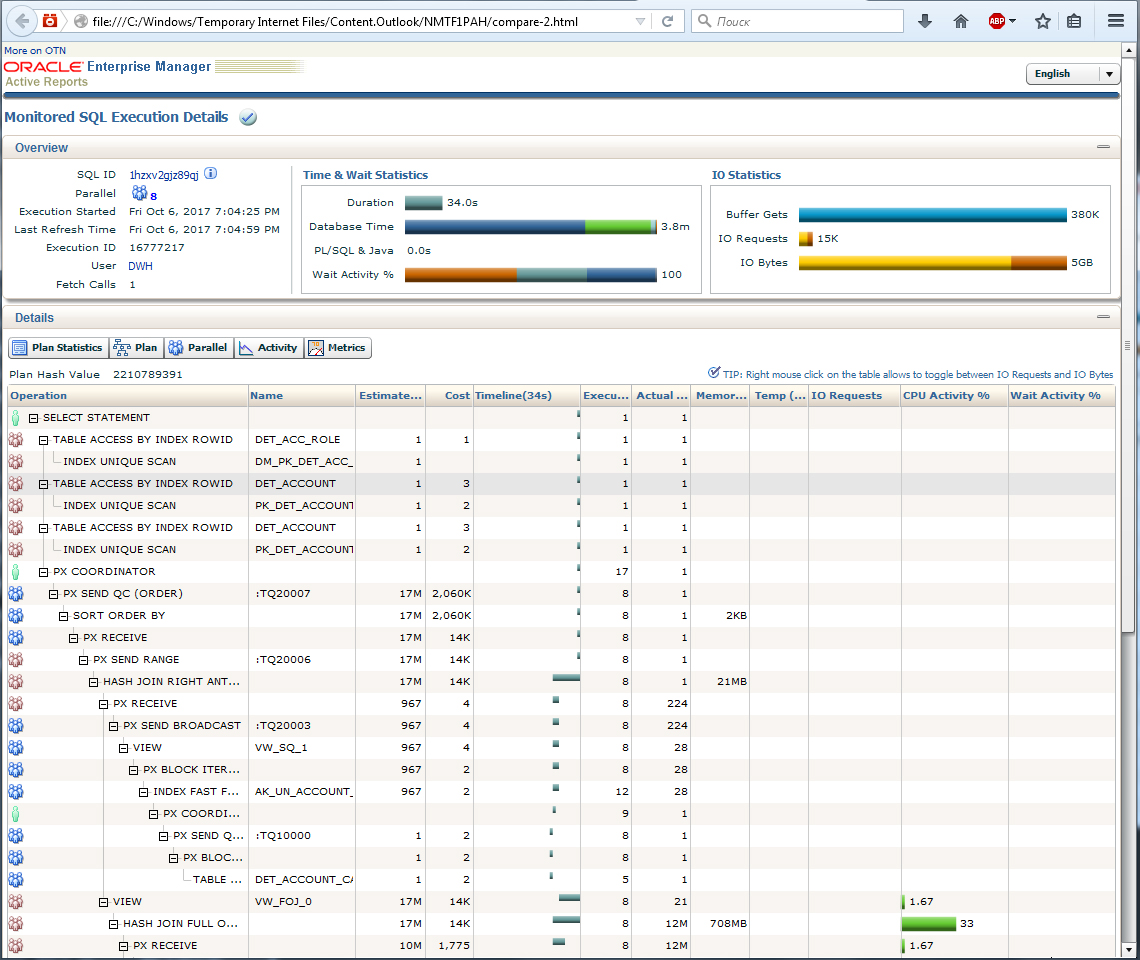
Рассмотрим пример подобной простой модификации (рис. 10). Как видите, изначально запрос выполнялся 3,6 минуты.
Запрос, требующий оптимизации (Рис. 10)
После простого распараллеливания на 8 потоков запрос начал выполняться 34 секунды. При этом его DB Time сохранился прежним и составляет 3,8 минуты. В целом соотношение 228 сек / 34 сек = 6,7 и близко к искомым 8 потокам, поэтому можно считать распараллеливание успешным (рис. 11). Интересно, что второй запрос потребовал меньше ресурсов для ввода-вывода данных, что не вполне типично.
Результат оптимизации путем запараллеливания обработки (Рис. 11)
Обратите внимание на еще один пример (рис. 12). Идет вставка данных во временную таблицу. Здесь уже была предпринята попытка распараллеливания, но эффективна ли она? Мы видим «одиноких копателей», которые заняты, например, задачей Load table conventional. И общая эффективность 1,7 минут wall time против 3,6 минут DB-Time никак не дает коэффициент, хоть сколько-нибудь похожий на 8.
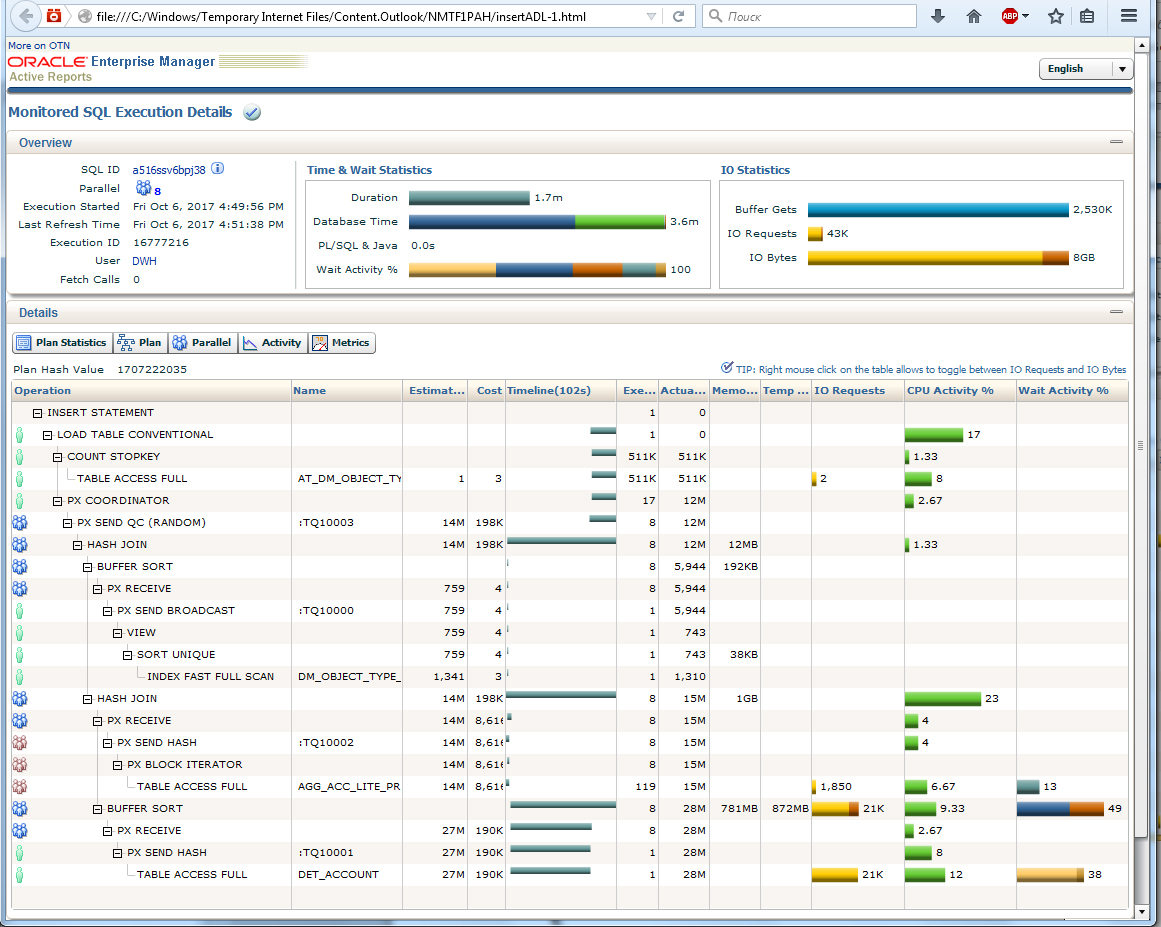
Еще один запрос, требующий оптимизации (Рис. 12)
В данном случае пришлось удалить ненужный индекс, перевести insert на прямую работу с PGA (load as select). Результат не заставил себя ждать (рис. 13). Теперь в одиночку, как положено, работает только один начальник — PX Coordinator. Все подчиненные работают группами. Время выполнения — 7 секунд, общая эффективность 57/7 — даже чуть больше 8 (ошибка округления в wall time). Как видим, запрос работает уже достаточно эффективно, и дальнейшие попытки его оптимизации большого эффекта не дадут.
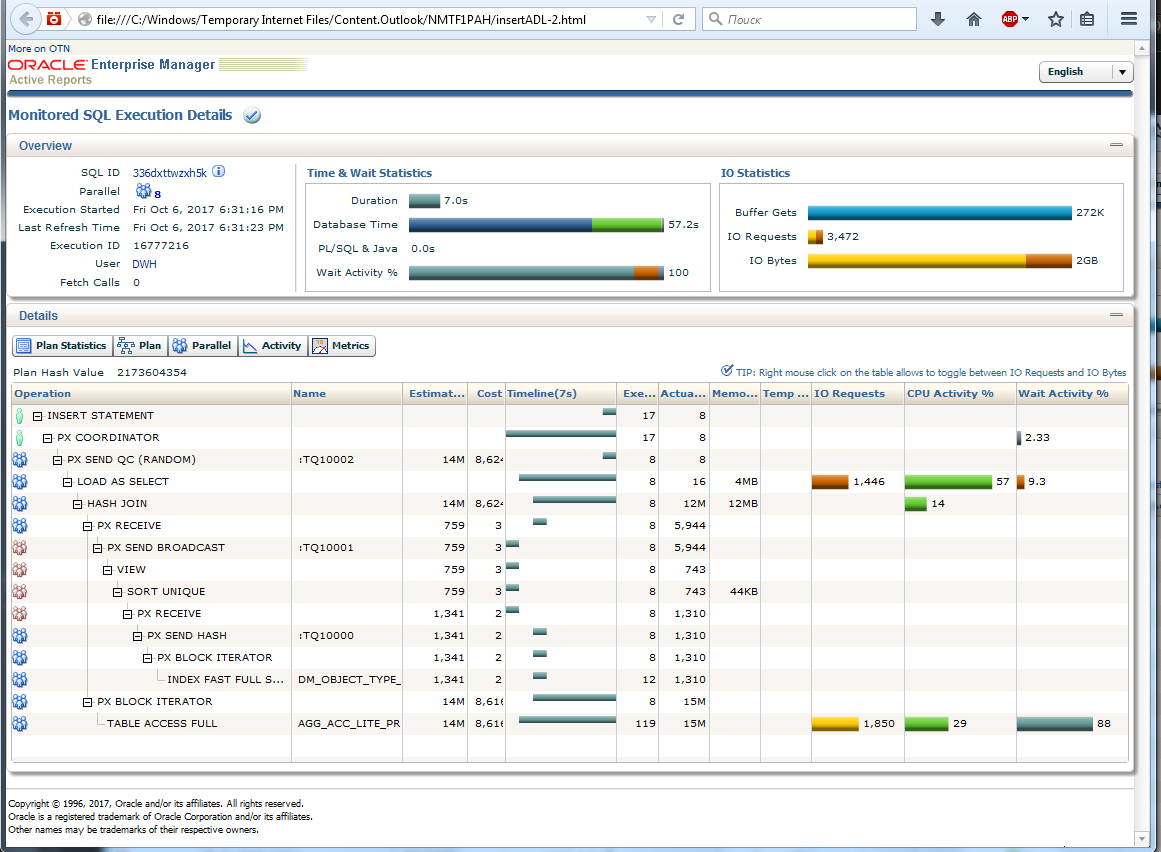
Результат оптимизации (Рис.13)
И в завершение приведу еще один пример, довольно забавный. Взгляните на SQL Monitoring запроса, на который пожаловались, что он «висит» (рис. 14). На самом деле он не висел, а очень активно работал на протяжении 20 часов. За это время бедный сервер «перелопатил» 57 Тбайт! И это при общем объеме базы всего лишь 80 Гб.
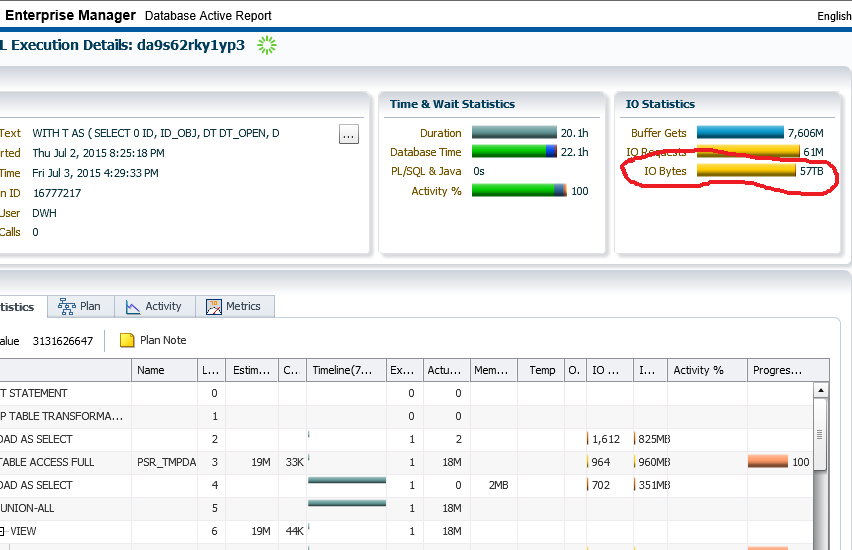
«Подвисший» запрос
В данном случае оптимизация не даже не предпринималась, запрос был отправлен на кардинальное переписывание.
Кое-что еще из физики процесса
Важно понимать, до какой степени «тяжелый» запрос может быть оптимизирован. Один из базовых показателей здесь — скорость чтения/записи СХД. Получить представление о текущей скорости очень просто: достаточно зайти на сервер и выполнить копирование большого файла. Либо выполнить простой запрос, который только читает данные и вычисляет count(*), а затем просмотреть его SQL Monitoring.
Для обычного жесткого диска такая скорость составляет порядка 200 Мб/сек. Это своего рода «скорость света» для данной системы — максимальная теоретически достижимая.
Если мы имеем запрос, который должен считать 5 Гб данных, обработать их и записать те же 5 Гб данных в другую область, то он не может работать быстрее, чем (5+5)/0,2 = 50 сек.
Таким образом, можно примерно вычислить, насколько данный запрос близок к идеалу. Конечно, с учетом того, что часть данных берется из буфера и есть дополнительные промежуточные операции.
Итак, мы рассмотрели общие принципы оптимизации и, следовательно, уменьшения DB Time на сервере. А если уменьшается DB Time, то, соответственно, отдаляется та грань, за которой «железо» перестанет справляться с нагрузкой и потребует обновления.
Другие методы оптимизации
Конечно, в нашей статье мы продемонстрировали далеко не все возможные методы оптимизации. Как минимум, в прикладной части также активно используются:
- Добавление индексов
- Удаление ненужных индексов
- Удаление ненужных constraints
- Избавление от WITH в сложных запросах
- Уход от больших циклов в PL/SQL, перевод их на SQL
- Тщательный сбор и установка статистики, в том числе посреди процесса
- Партиционирование (иначе – секционирование) таблиц
- Увеличение объема памяти для сортировки
Со стороны «железной» и административной части применяются такие методы, как:
- Перевод сегментов TEMP на быстрые носители или даже в RAM-диск
- Вычисление горячих областей и перевод их на быстрые носители, например на SSD
- Изучение эффективности работы журналов и при необходимости перевод их на быстрые носители
- Оптимизация параметров БД
Подведем итоги
Исходя из имеющегося у нас опыта по оптимизации систем, можно сделать следующие выводы:
1. При желании практически любой запрос можно оптимизировать в 5-10 и даже более раз.
2. В первую очередь оптимизации требуют процессы, лежащие на критическом пути (те самые 20% запросов, обеспечивающие 80% результата).
Обладая всеми этими знаниями, подойдя к той грани, когда еще недавно удовлетворяющее вашим потребностям оборудование становится бесполезным железом, вы всегда сможете распорядиться имеющимися ресурсами наиболее эффективно. Вполне вероятно, что, сравнив стоимость работ по оптимизации и стоимость приобретения нового оборудования, вы примите решение «не спешить выбрасывать старый диван», ведь он еще сможет послужить вам несколько лет.



, теряет производительность. Например, запрос к серверу, который изначально выполнялся буквально одну секунду, стал отрабатывать за 15 или даже 20 секунд. При этом довольно часто отчет о производительности (AWR-отчет) может свидетельствовать о нормальном функционировании ПО. Что […]&image=https://www.softlab.ru/blog/wp-content/uploads/2024/02/snapedit_1708344480203-1.jpg){kind=link}